
1/4
July 1, 2026 · 2:49 PM
MoonBit:新语言也能被AI学会
量子位文章图片笔记:用四张卡看懂 MoonBit 为什么能作为新语言样本,展示大模型从几乎不会写到通过继续预训练与指令迁移达到 32.60% McEval-Hard pass@1 的路径。

原文来自量子位,发布时间为 2026-07-01 13:53。本期把《冷门新语言 AI 写不动?IEEE 论文:从零到及格线,MoonBit 给出完整训练路线》整理成四张图片笔记,方便快速转发和复盘。1
这篇文章讨论的不是某个模型又刷了新分数,而是一门新编程语言怎样让模型「真正学过」。论文《No Resource, No Benchmarks, No Problem?》把 MoonBit 和 Gleam 作为 no-resource languages 来测,比较高资源、低资源和无资源语言上的代码生成差异。2
图片笔记
- 封面|新语言也能被 AI 学会 这篇论文的主线很直接:模型一开始几乎不会写 MoonBit,但经过继续预训练和指令迁移后,MoonBit 在 McEval-Hard 上能达到 32.60% pass@1。2
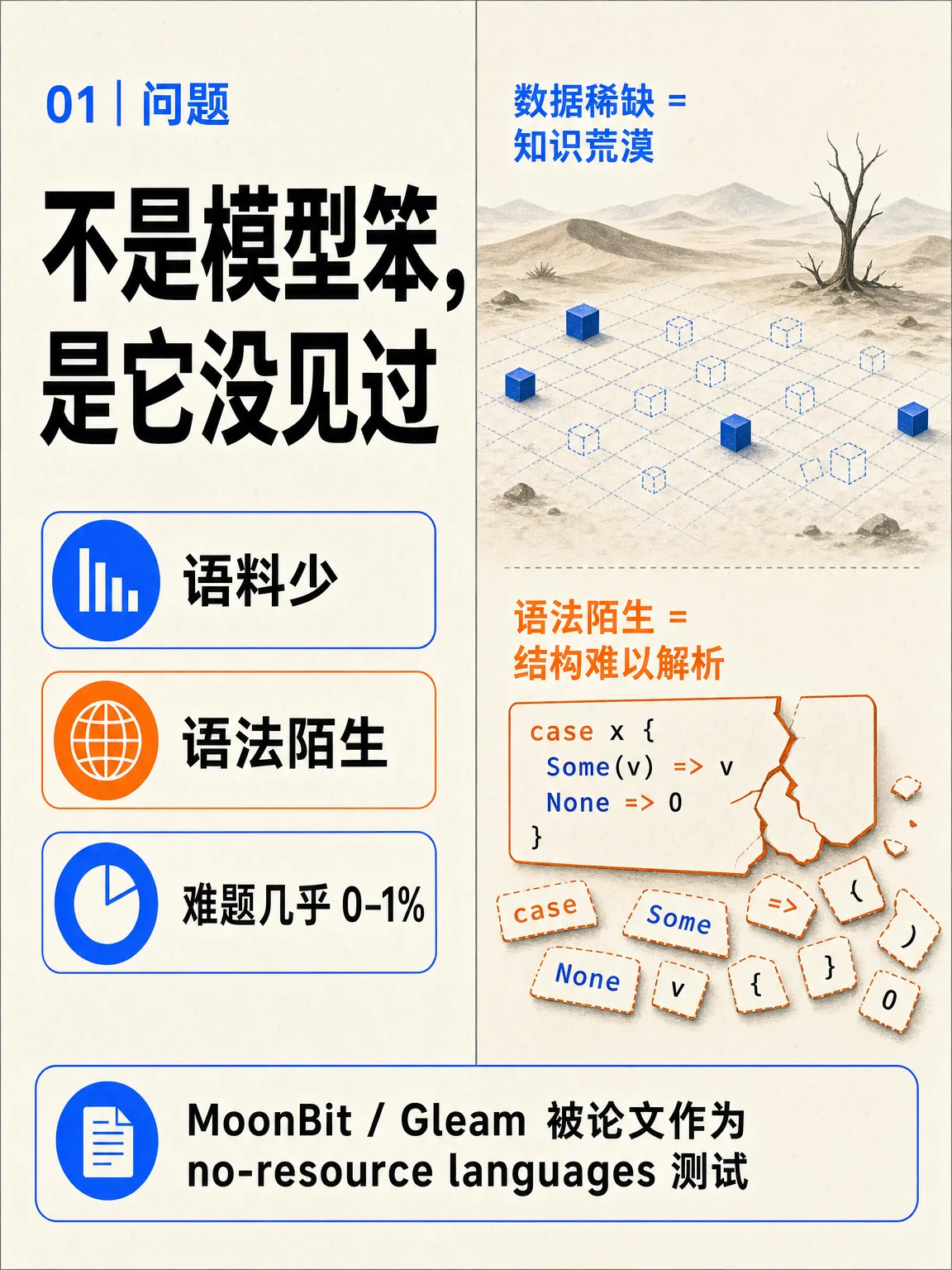
- 问题|不是模型笨,是它没见过 论文指出,MoonBit、Gleam 这类新语言的公开仓库和训练语料远少于 Python、Java;在更难的 McEval-Hard 上,无资源语言零样本表现只有 0% 到 1% 左右。2
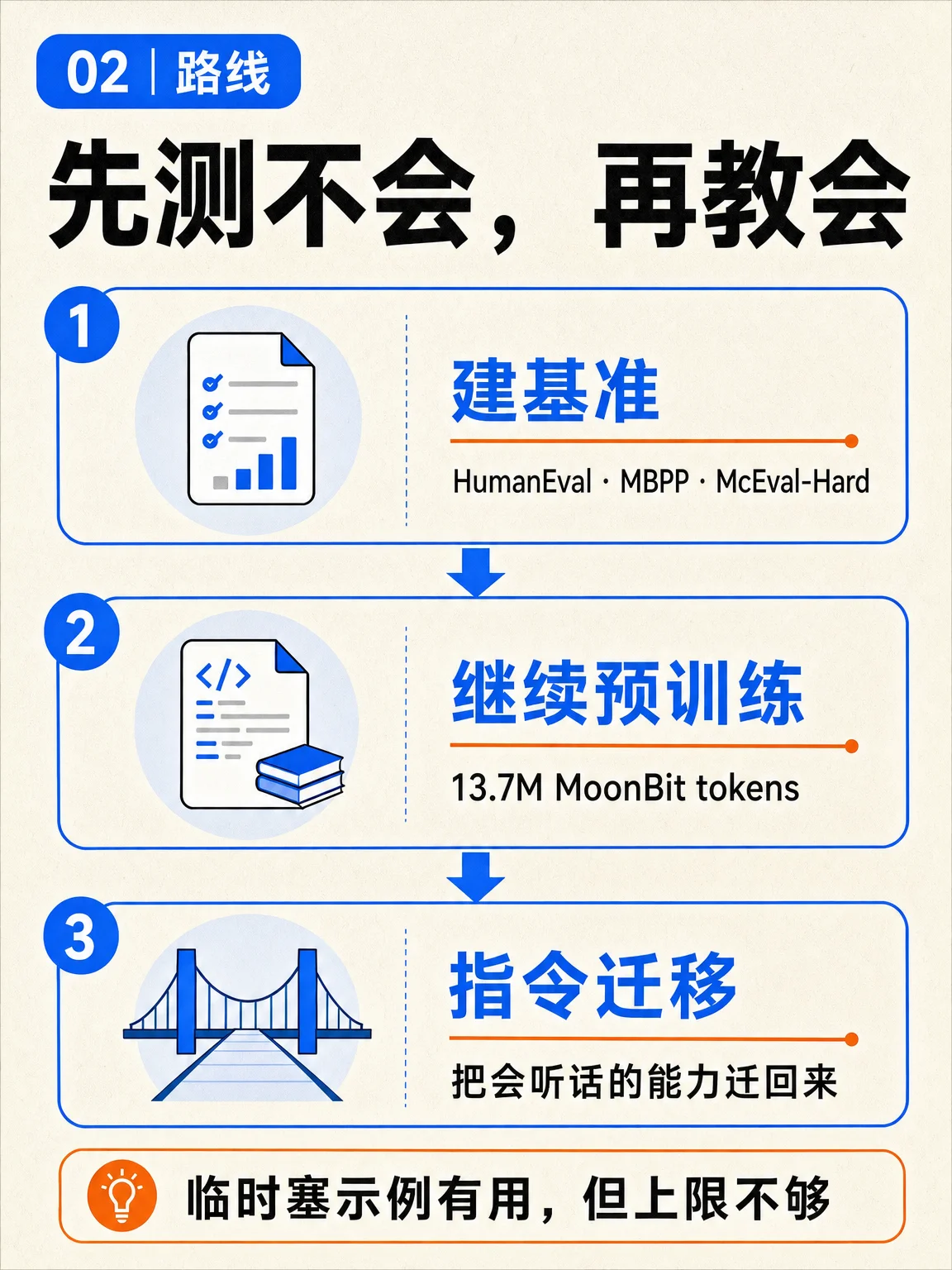
- 结果|从不会写到及格线 在 Qwen 2.5 Coder 32B 上,instruction transferring 后的 MoonBit pass@1 达到 HumanEval 50.71%、MBPP 53.04%、McEval-Hard 32.60%。2
读完这篇,最值得带走的一点
AI 时代的新语言不能只等大模型自然覆盖。MoonBit 官方曾强调 flattened design、顶层定义强制类型签名和结构化接口实现,这些设计让代码更适合线性生成,也更利于 RAG、decoder correction、backtrack 等场景。3
换句话说,代码、文档、工具链和基准都可以变成训练资产。新语言想让 AI 写得好,生态建设要从人类开发者延伸到模型开发者。
Comments
Sign in to comment.